Datasets
Contents
Datasets¶
We need to download some data for the examples. Some files are bundled with the notebooks because I am not smart enough to understand how to download them through the various web / ftp interfaces directly or I needed to filter or compress the information for the purposes of the class. Please go to the original sites if you need to use these data for anything other than the demonstrations in these notebooks.
Most datasets are too large for the repository (and generally, that’s not a place to keep anything which is not the primary target of revision management. The bundled data are compressed and will be unpacked (copied) to the ../../Data/Resources directory by the “download” functions in this notebook. If you mess them up, just run the download again. Anything that is undamaged will just be be skipped anyway.
Global Magnetic Data¶
Magnetic intensity data from geomag.org
Topography data¶
ETOPO1 images are from NOAA - we use their geotifs which are subsampled from the original (enormous) dataset but
NASA Blue marble images¶
Winter and Summer images for the Earth are grabbed for plotting examples. The winter ones (June) are used by default as these have less ice in the N. Hemisphere.
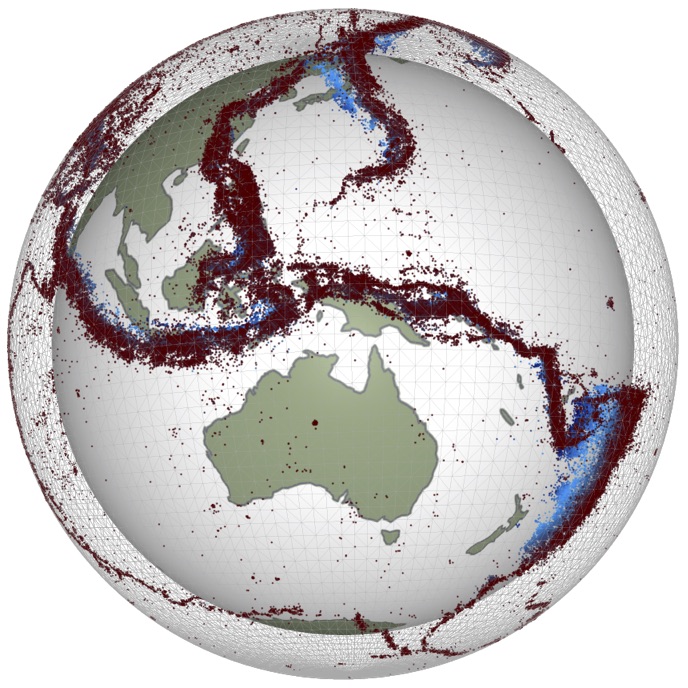
Earthquake hypocentres¶
Are grabbed from the NEIC - they are in the geoJSON format since that is very simple to read with python. The downloads are limited at 20k events so the time and magnitude range is whatever it takes to get just under this limit. The filenames give clues about that, but, so does the catalogue itself once it is read in.
Global age grid¶
Taken from Earthbyte and reduced in size by throwing away the grid information and saving in compressed numpy format.
Global strain rate¶
I grabbed the second invariant of the strain rate from the global strain rate map project through the ‘Jules Vernes’ portal.
%%sh
ls -l Resources/
The datasets that we use for this course are kept in a central location.¶
These can be downloaded on demand from the cloudstor service which is provided by AARNET. Anyone with an Australian university affiliation can ask for substantial storage on cloudstor and it is a fast, reliable service.
Why do I do that ?
So if you happen to delete or break one of the datasets, we can just get a new copy. Also, these kinds of data are not allowed on revision control sites like Github because they are large binary files and break the notion of revision control.
There is a python module cloudstor that can grab data anonymously from read-only folders.
from cloudstor import cloudstor
teaching_data = cloudstor(url="L93TxcmtLQzcfbk", password='')
teaching_data.list()
from cloudstor import cloudstor
teaching_data = cloudstor(url="L93TxcmtLQzcfbk", password='')
teaching_data.list()
download_list = [
'AusMagAll.tiff',
'BlueMarbleNG-TB_2004-12-01_rgb_3600x1800.TIFF',
'EMAG2_image_V2_Small.tif',
'EMAG2_image_V2_no_compr.tif',
'ETOPO1_Ice_c_geotiff.tif',
'Etopo1_3600x1800.tif',
'color_etopo1_ice_low.tif',
'etopo1_grayscale_hillshade.tif',
'etopo1_grayscale_hillshade_small.tif',
'events_4.5+by_year_1970-2019.npy',
'global_age_data.3.6.z.npz',
'sec_invariant_strain_0.2.dat',
'velocity_AU.nc',
'velocity_EU.nc',
'velocity_IN.nc',
'velocity_NA.nc',
'velocity_NNR.nc',
'velocity_OK.nc',
'velocity_PA.nc'
]
for file in download_list:
import os
# Check if it exists already / is the same size
teaching_data.download_file_if_distinct(file, os.path.join("Resources",file))
ls Resources/
# This is how we download a whole directory - we don't have a size-check comparison for that case
teaching_data.download_directory("EQs","Resources/EQs")
teaching_data.download_directory("HYP_50M_SR_W","Resources/HYP_50M_SR_W")
teaching_data.download_directory("OB_50M","Resources/OB_50M")
# Extract any files that were downloaded as zip archives (keep the originals to avoid re-downloading)
import zipfile
import glob
for zipped in glob.glob("Resources/*.zip"):
with zipfile.ZipFile(zipped) as zf:
zf.extractall("Resources")
print ("Unzipped {}".format(zipped))